周四新MAC到了,周五到今天就折腾了三天。
其实,也不是第一次用MAC,以前也有一台MBA,但那时是个人使用,主要就上上网、看看视频。这台则是跟公司申请的,用于工作。
首先,对标之前在windows上的习惯,安装了一些软件,记录如下:
Chrome:我上网基本只认它,保存了大量书签和插件,与之前的windows完全一致。
Sketch:这是我申请MAC的理由,听说是产品设计利器,windows上没有,还没用过。
Axure RP:...
一、
我应该是08/09年左右开始使用五笔,一直用的86版。中途有过换输入法的想法,但一般没有过多折腾,最近两个月却心血来潮,反复折腾。
首先是去年11月上换了拼音输入法,原因有二,一是手机上一直使用T9拼音,希望手机和电脑使用相同的输入法,手机上转五笔的成本相对更高,所以选择拼音;二是有时候会打些繁体字,拼音能够使简繁输入体验保持一致,五笔则不行,86版五笔是为简体设计的。就这样用了一个...
这两天因为要处理XML,研究了一下lxml库,做个总结。
我在处理XML时,最想了解的三个问题是:
问题1:有一个XML文件,如何解析
问题2:解析后,如果查找、定位某个标签
问题3:定位后如何操作标签,比如访问属性、文本内容等
本文就是按这三个问题组织的,文本中代码都在Python 3.5中运行通过。
开始之前,首先是导入模块,该库常用的XML处理功能都在lxml.etree中,可用下面的语句导入:
>>> fr...
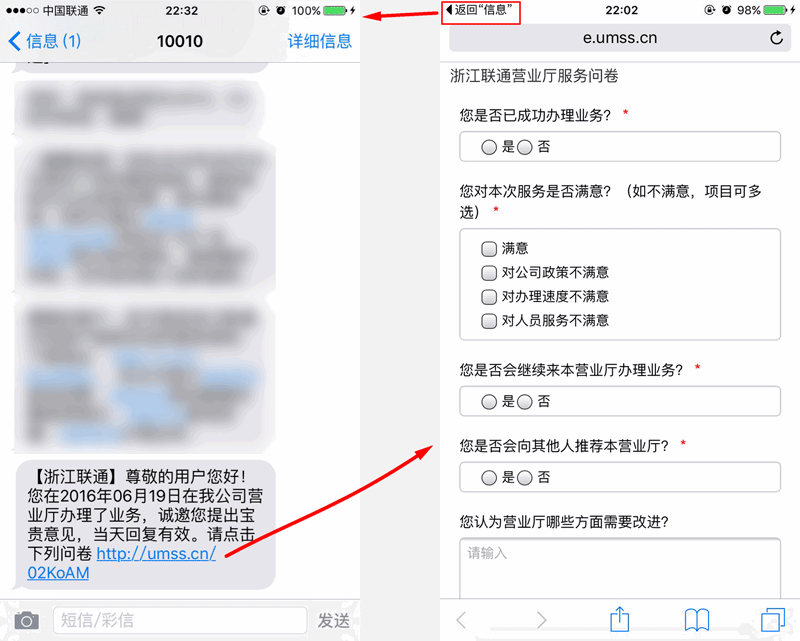
注:想看6s的使用小技巧,可直接看后面带标题的段落。
我是14年的时候买的iPhone4s,而且还是2年的合约机,那个时候4s都已经问世三年了,哎……。
在那之前是一个SONY,5寸屏,所以刚开始用4s的时候,不太习惯,但没多久就爱上小屏幕了,单手的操控感真的很爽。另外4s的外观和做工非常赞,喜欢它的棱角分明和玻璃背面。
不过,后来各种APP越做越大,手机的空间越来越拮据,APP运行越来越卡,而且很多都不再支...
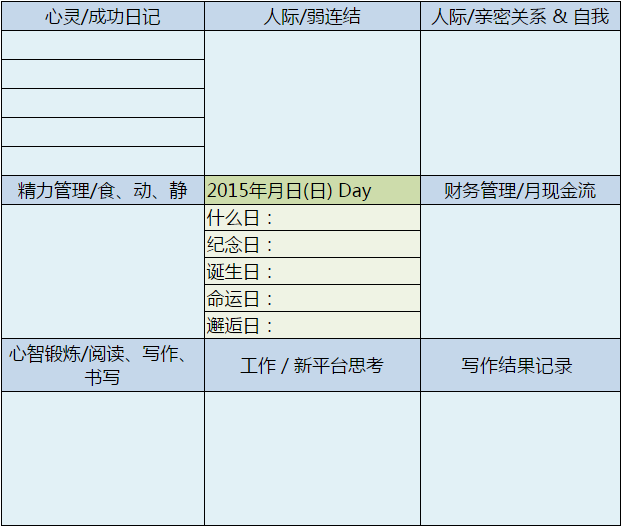
研究过时间管理方法的人,应该都会听过晨间日记,它是佐藤传提出的一种写日记的方法。字面上看,就是每天早上写日记。
为什么是早上
相比于晚上写日记,早上写有几个好处:
冷静之后再写的大不同。经过一晚上的休息,能更客观的看待问题
短时间内可以正确记录。虽然隔了一晚,但对前一天事情仍可记忆犹新,正确记录
「未来日记」可改变当日行动模式。写下自己的想法,让自己变得更加稳定,可以发变行动。...
奇特的一生
大四找工作期间,发现一本奇书《奇特的一生》,俄国作家格拉宁写的。12年时这本书是绝版的(13年有再版),当时是将pdf打印出来看的。书中主人公是前苏联科学家柳比歇夫,他是昆虫领域的专家,同时在数学、哲学等方面亦有极深的造诣。格拉宁通过整理研究他的日记和文档,发现了他成功的秘密,也就是今天被称为「柳比歇夫时间统计法」的一套时间管理方法。
经常有人说「时间就是金钱」,在金钱...
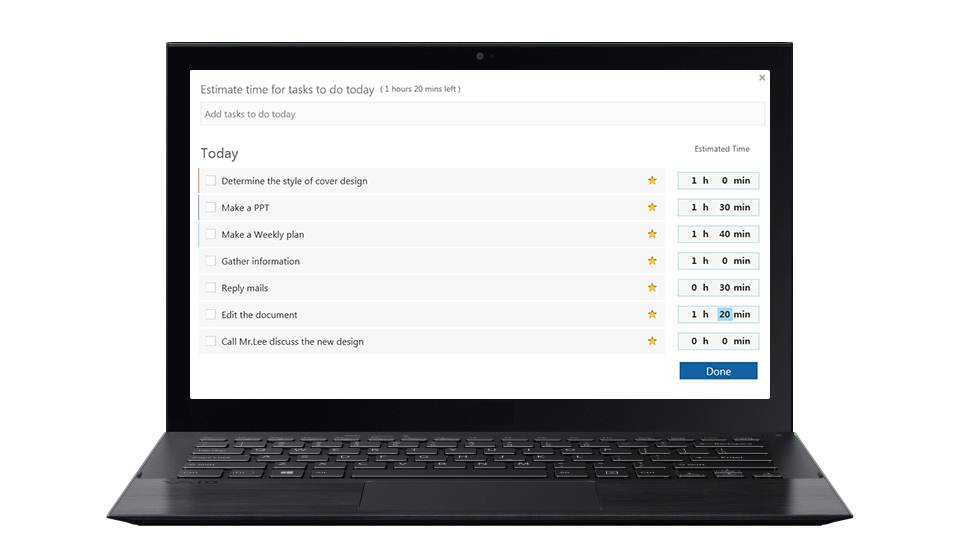
自从2001年David Allen出版他的《Get Things Done》后,GTD便成了专有名词,成为时间管理领域最流行的方法之一。但它本身只是方法,操作起来还需要一套工具。作者原著中,主要是使用纸笔,但随着计算机及互联网的发展,围绕GTD衍生出了大量商业软件。本文将介绍几款比较出名、且功能强大的。
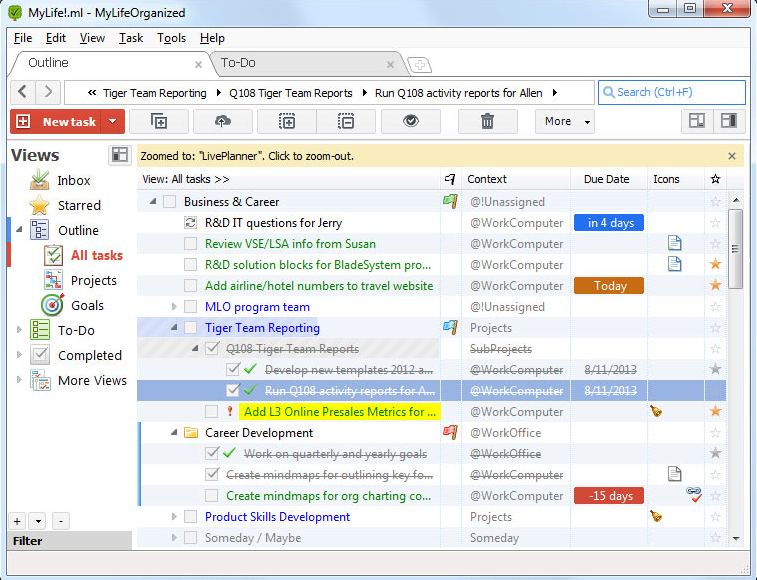
Omnifocus
Omnifocus
适用平台:苹果系列,包括iPhone、iPad、Mac官方网站:https://www.omnigroup.com/omnifocu...
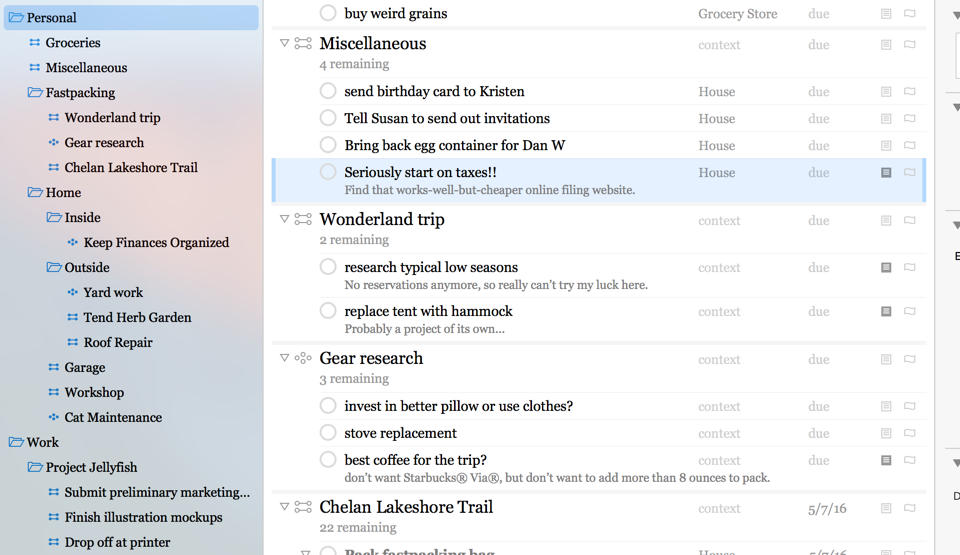
作为一名职场螺丝钉,工作上的事通常都比较单一,不涉及复杂的管理,但还是常常出现丢三落四,或是放着重要的任务不处理却忙于各种无关紧要的小事。为了改变这种状况,看了不少时间管理方面的资料,涉及有GTD、柳比歇夫时间统计法和晨间日记。今天开始,用几篇文章介绍这些方法,首先来看GTD。
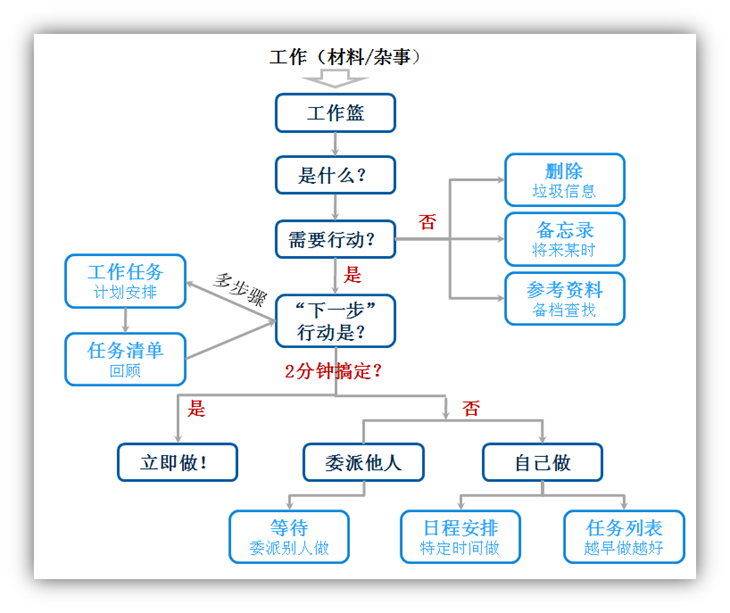
GTD是Get Things Done的缩写,是David Allen提出的一套个人时间管理系统,名称是来自他的书名,中文版译为《搞...
接上篇《Python 爬虫:模拟登录知乎》。
分析页面请求
LZ准备从知乎的话题页抓取所有的话题及其结构,在页面上获取话题共有两类ajax request,分别是「显示子话题」和「加载更多」,两者都是一次输出10个话题。request url如下:
https://www.zhihu.com/topic/19776749/organize/entire?child=&parent=19552706
其中child和parent是话题的ID,「显示子话题」只需要parent参数,「加载更多」则两个参数...
在BeautifulSoup中,用contents或children遍历子节点的时候,如果节点下存在字符串,则会同时获取Tag和NavigalbeString对象。这是一个非常坑爹的特性,一方面通常获取子节点主要是得到Tag,另一方面,bs已经提供了strings及stripped_strings单独获取节点下的字符串,这里就是多此一举。
下面以contents为例,来看看这个问题的具体情况并给出两种解决方案。
一个例子
假设有下面这个xml:
<tab>
<t...